
作者:机器之心
今天要介绍的是 mPLUG-Owl,该工作不仅通过大量 cases 展示出优秀的多模态能力,还第一次针对视觉相关的指令理解提出一个全⾯的测试集 OwlEval,通过人工评测对比了已有模型,包括 LLaVA 、MiniGPT-4 、BLIP-2 以及系统类 MM-REACT 等工作,实验结果表明 mPLUG-Owl 展示出更优的多模态能力,尤其在多模态指令理解能力、多轮对话能力、知识推理能力等方⾯表现突出

论文链接:https://arxiv.org/abs/2304.14178
代码链接:https://github.com/X-PLUG/mPLUG-Owl
ModelScope体验地址:
https://modelscope.cn/studios/damo/mPLUG-Owl/summary
HuggingFace体验地址:
https://huggingface.co/spaces/MAGAer13/mPLUG-Owl
多模态能力展示
我们把 mPLUG-Owl 与现有工作进行对比来感受一下 mPLUG-Owl 的多模态效果,值得一提的是,该工作中评比的测试样例基本上都来自已有工作,避免了 cherry pick 问题。
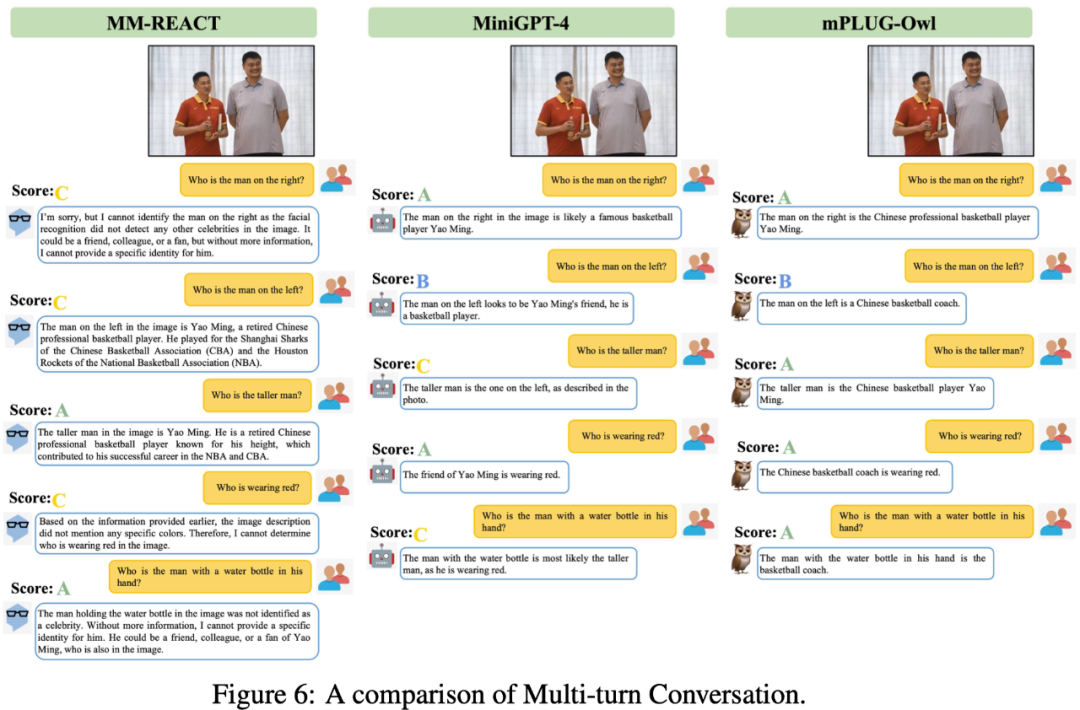
下图 6 展示了 mPLUG-Owl 很强的多轮对话能力。
从图 7 中可以发现, mPLUG-Owl 具有很强的推理能力。

如图 9 展示了一些笑话解释例⼦。

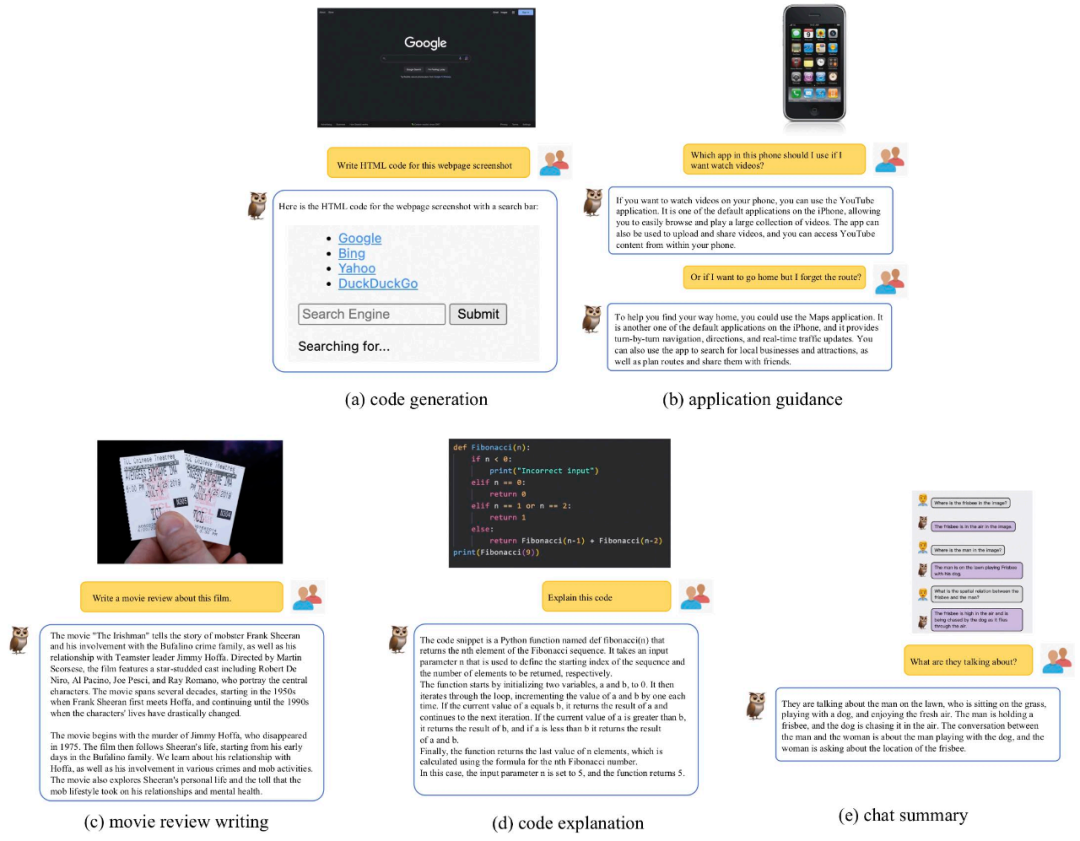
在该工作中,除了评测对比外,该研究团队还观察到 mPLUG-Owl 初显一些意想不到的能力,比如多图关联、多语⾔、文字识别和文档理解等能力。
如图 10 所示,虽然在训练阶段并没有进行多图关联数据的训练,mPLUG-Owl 展现出了一定的多图关联能力。

如图 11 所示,尽管 mPLUG-Owl 在训练阶段仅使用了英文数据,但其展现出了有趣的多语⾔能力。这可能是因为 mPLUG-Owl 中的语⾔模型使用了 LLaMA,从而出现了这一现象。

尽管 mPLUG-Owl 没有在带有标注的文档数据上进行训练,但其仍然展现出了一定的文字识别和文档理解能力,测试结果如图 12 所示。
方法介绍
该工作提出的 mPLUG-Owl,其整体架构如图 2 所示。
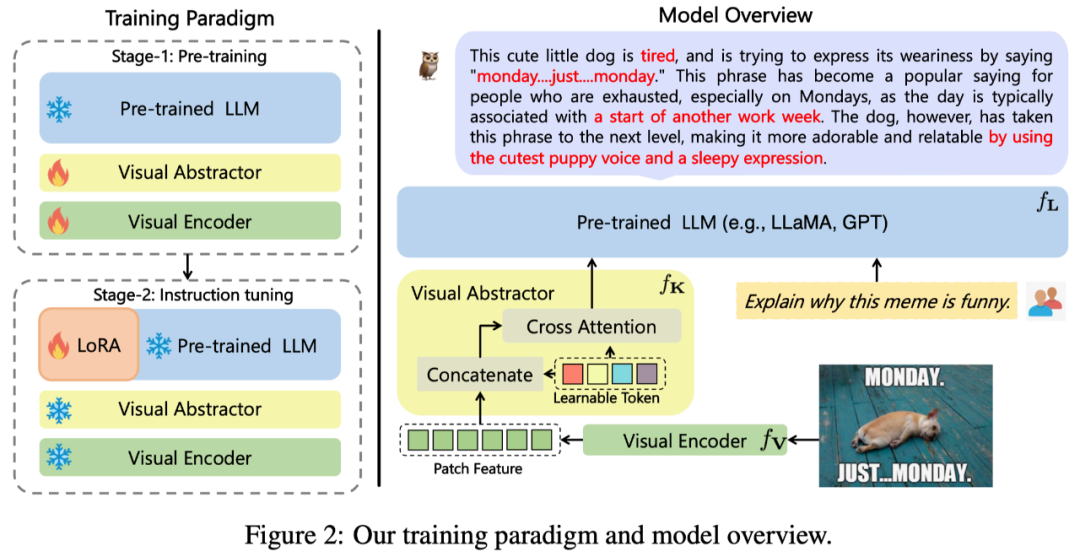
模型结构:它由视觉基础模块 Fv (开源的 ViT-L)、视觉抽象模块 Fx 以及预训练语⾔模型 Fl ( LLaMA-7B) 组成。视觉抽象模块将较⻓的、细粒度的图像特征概括为少量可学习的 Token,从而实现对视觉信息的⾼效建模。⽣成的视觉 Token 与文本查询一起输⼊到语⾔模型中,以⽣成相应的回复。
模型训练:采用两阶段的训练方式
第一阶段:主要目的也是先学习视觉和语⾔模态间的对⻬。不同于先前的工作, mPLUG-Owl 提出冻住视觉基础模块会限制模型关联视觉知识和文本知识的能力。 因此 mPLUG-Owl 在第一阶段只冻住 LLM 的参数,采用 LAION-400M, COYO-700M, CC 以及 MSCOCO 训练视觉基础模块和视觉摘要模块。
第⼆阶段:延续 mPLUG 和 mPLUG-2 中不同模态混合训练对彼此有收益的发现,Owl 在第⼆阶段的指令微调训练中也同时采用了纯文本的指令数据 (52kfrom Alpaca+90k from Vicuna+50k from Baize) 和多模态的指令数据 (150k from LLaVA)。作者通过详细的消融实验验证了引⼊纯文本指令微调在指令理解等方⾯带来的收益。第⼆阶段中视觉基础模块、视觉摘要模块和原始 LLM 的参数都被冻住,参考 LoRA,只在 LLM 引⼊少量参数的 adapter 结构用于指令微调。
实验结果
SOTA 对比
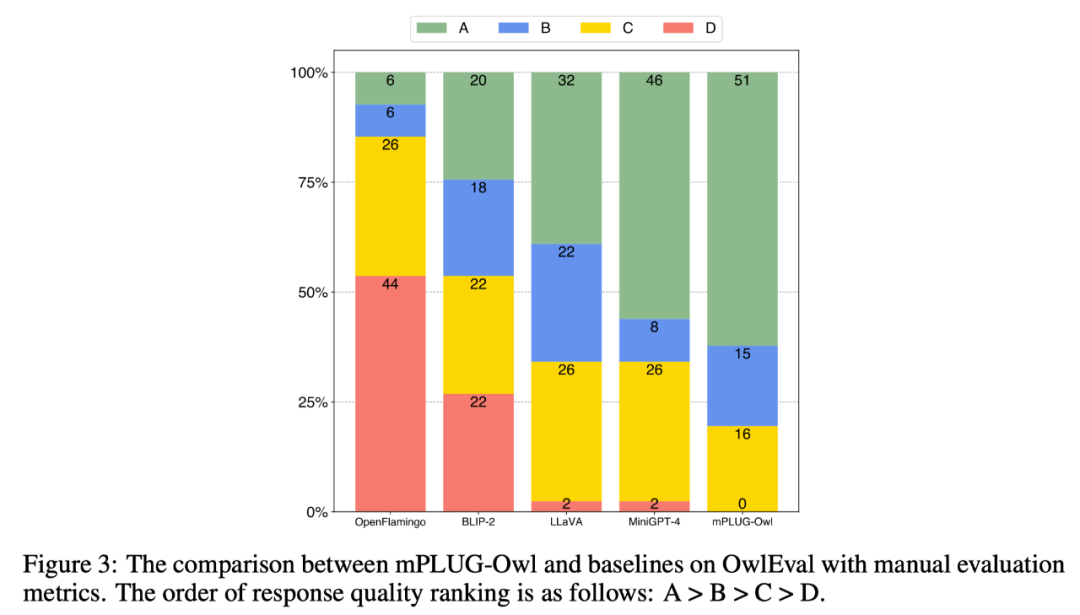
为了比较不同模型的多模态能力,该工作构建一个多模态指令评测集 OwlEval。由于⽬前并没有合适的自动化指标,参考 Self-Intruct 对模型的回复进行人工评测,打分规则为:A="正确且令人满意";B="有一些不完美,但可以接受";C="理解了指令但是回复存在明显错误";D="完全不相关或不正确的回复"。
对比结果如下图 3 所示,实验证明 Owl 在视觉相关的指令回复任务上优于已有的 OpenFlamingo 、BLIP-2 、LLaVA、MiniGPT-4。
多维度能力对比
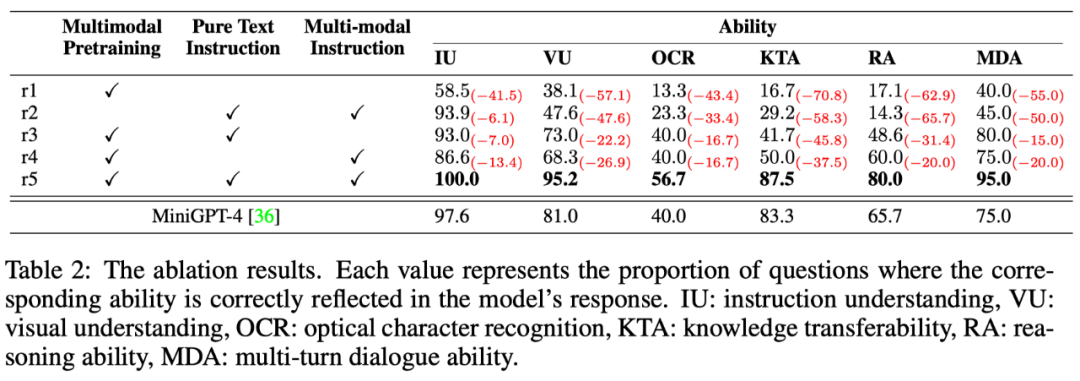
多模态指令回复任务中牵扯到多种能力,例如指令理解、视觉理解、图⽚上文字理解以及推理等。为了细粒度地探究模型在不同能力上的⽔平,本文进一步定义了多模态场景中的 6 种主要的能力,并对 OwlEval 每个测试指令人工标注了相关的能力要求以及模型的回复中体现了哪些能力。
结果如下表格 6 所示,在该部分实验,作者既进行了 Owl 的消融实验,验证了训练策略和多模态指令微调数据的有效性,也和上一个实验中表现最佳的 baseline— MiniGPT4 进行了对比,结果显示 Owl 在各个能力方⾯都优于 MiniGPT4。
来源:https://www.jiqizhixin.com/articles/2023-05-07-2
所有评论