
一个用于理解数据网络效应和现有企业在你所在行业的优势以及对你的影响的简单框架。
导言
当你进入创投界时,你很快就会明白投资的关键在于寻找Moats。为什么呢?我找不到比以下这篇文章中Gil Dibner的解释更好的方式来解释了。
简而言之:风险投资家正在寻找在未来5-10年内可能价值数亿或数十亿美元的公司,条件是:
- 预计未来现金流代表估值。
- 盈利能力代表预计未来现金流。
- Moats代表盈利能力。
为什么Moats代表盈利能力?简单来说,因为Moats增加了企业在与供应商和客户的交涉中的议价能力,帮助企业提高价格和降低成本以实现更高的利润。这个简单的推理结果是,风险投资家会寻找正在创建Moats的公司。
市场中的网络效应是Moats的一个很好的例子。在AirBnB上有越多的可租住的地方,需求就越有可能涌向该平台,进而吸引更多房主在AirBnB上出租他们的房源。这就形成了循环闭合。
这种机制产生了一个赢者通吃的动态,往往市场中具有这种动态的最大的参与者远远超过竞争对手。这就是为什么投资者喜欢市场的简要原因。如果你足够幸运选择到市场的赢家,很有可能会获得高额回报。
一、AI公司的特殊之处
现在,有趣的一点是,AI带来了一种被一些人称为“数据网络效应”的新型网络效应。机器学习算法需要数据才能运行。虽然这种关系不是线性的(稍后会详细说明),但随着机器学习算法吸收更多的数据,其预测/分类工作的准确性会提高。
这种机制将遵循以下过程:随着公司吸引更多的客户,它从每个客户那里获得更多的数据来训练和优化其算法。有了更多的数据,预测的准确性提高了,产品的整体质量也提高了。更好的产品有助于说服新客户购买并贡献他们的数据,循环就此闭合。
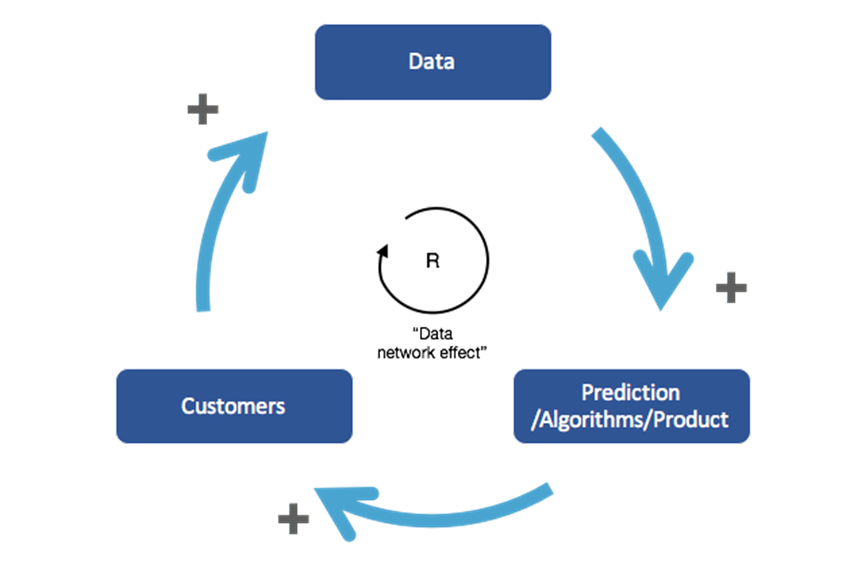
而美妙的是,这个机制帮助AI公司沿着客户适应周期前进。早期适应的客户对于初始的错误或不是呢么优秀的性能够更加容忍。通过他们的数据和反馈意见,帮助AI企业建立更好的算法,并吸引那些较晚阶段适应的成为客户。
另外,还有一个自我强化的反馈循环也在起作用,我们可以称之为“人才吸引循环”。公司拥有的数据越多,对于数据科学家来说,它就越具有吸引力,因此团队吸引到优秀人才来帮助构建最佳的机器学习产品的机会就越高。
用Yoshua Bengio的一句话来总结很好:“人工智能是一种自然而然地倾向于赢者通吃的技术[...]在技术上占据主导地位的国家和公司将随时间获得更多的权力。更多的数据和更大的客户群体为你提供了难以撼动的优势。这种公司也是科学家想去的最好的地方。拥有最好研究实验室的公司将吸引最优秀的人才。这就成就了财富和权力的集中。”(更多信息请参见此处)
问题在于初创企业最初几乎没有(或只有很少的)数据,仅能依靠少数有才华的个人(通常只有创始人)。就像市场的网络效应需要时间和资源来发挥作用一样,AI公司的自我强化循环也需要初始数据。
而谁拥有这些数据呢?
现有企业。
这就是为什么一些行业观察者指出现有企业在AI浪潮中拥有不公平的优势(详见Marc Andreessen的这次采访)。
对于AI投资者来说,令人振奋的消息是事情并不像看上去那么简单。在接下来的部分,我将概述一个框架来思考现有企业在AI领域的优势。
二、思考现有企业优势的一个框架
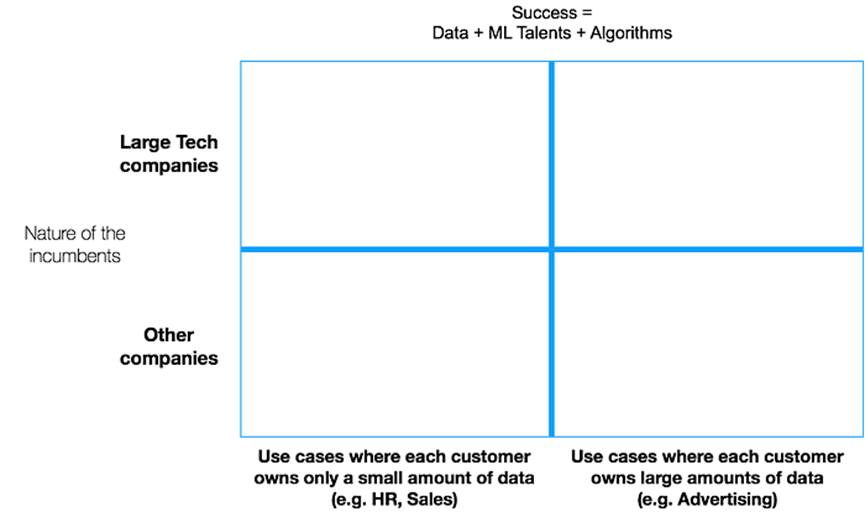
可能解释AI公司成功的部分原因的一个简单公式,与前面部分的图表相呼应:
AI的成功 = 数据 + 机器学习人才 + 算法
简单来说,成功且具有防御性的AI公司拥有“足够大的数据集,供机器学习领域的人才使用去创建最佳算法”。
思考现有企业在AI领域的优势的一个有用方法是看这个2X2矩阵——感谢Madkudu的创始人Sam Levan首次向我介绍这个概念——其中一个轴表示每种用例可用的数据量,另一个轴表示当前涉足每种用例的公司的性质(技术类和非技术类)。然后可以比较现有企业和初创企业在这个方程式的结果上的差异。
如果我们考虑那些由大型科技公司解决的案例,这些案例中每个潜在客户都拥有大量数据,那么现有企业的优势就非常强大。除了典型的现有企业优势(例如,接触客户的机会、更大的投资和承受亏损的能力),大型科技公司拥有多年积累的大量数据。
它们还能够借助品牌和大量的财务资源来吸引最优秀的机器学习的人才,这些人才将开发出最佳的算法。现有企业得分:3/3

在这种情况下,新创企业与科技巨头正面竞争似乎是不明智的。这就像从零开始与谷歌竞争一样。
但是现有企业的优势不仅在于该矩阵的这一部分。现在我们来看看右下角的部分。这部分由非技术公司解决,但每个潜在客户已经拥有大量的数据。以拥有多年收费数据的高速公路运营商为例。
历史已经证明,自深度学习出现以来,数据可能比算法本身更重要。Edge的这篇文章在这方面提供了一个有趣的示例:
“关键算法提案和相应进展之间的平均经过时间约为18年,而关键数据集的可用性和相应进展之间的平均经过时间不到3年,即快了约6倍,这表明数据集可能是进展的限制因素。”
此外,大型科技公司不断开源新的机器学习软件包,从而将算法变成商品,尤其是在目标识别、语言模型或语音识别等通用机器学习领域。由于通用机器学习的存在,那些拥有大量数据集的非技术公司以数据作为交换,使用在科技公司数据集上进行预训练的开源软件包来获得相关结果。
总结起来,一家大公司(不一定是科技公司),即使在内部可能没有顶尖的机器学习专家,也可能比一家小型初创企业构建出更好的AI产品。这仅仅是因为它可以获得比小型初创企业更多的数据。
在我们的例子中,高速公路运营商受益于许多竞争优势,这些优势使其免受初创企业(初期数据非常有限)的威胁。
因此,我们可能应该在方程式中给数据更高的权重,而不是机器学习人才:
成功 = 数据 * 数据 + 机器学习人才 + 算法
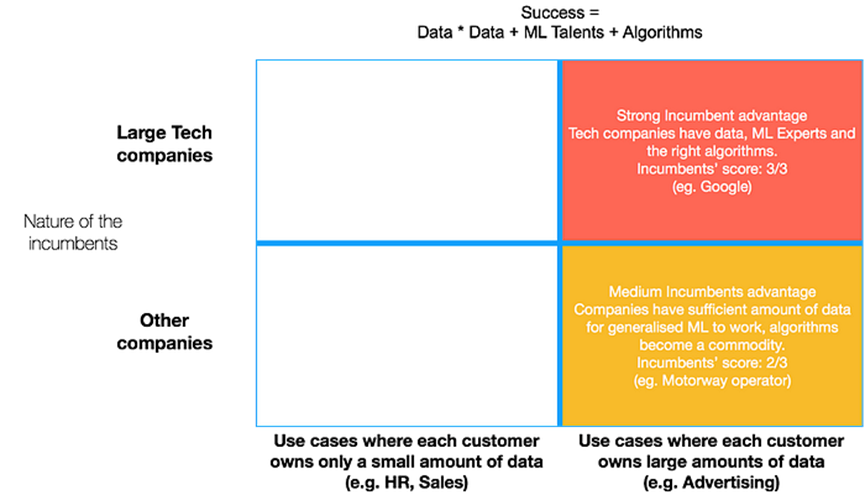
现在让我们来看矩阵的左上角部分:这些用例中,每个客户只有少量数据可用,但这些领域受到大型科技公司的关注。一个很好的例子是预测潜客户成为真正的客户的可能性(潜在客户评分)。每个潜在客户没有足够的数据来使用通用机器学习自行构建足够好的预测模型。
每个潜在客户在他们的CRM或市场自动化工具中可能只有数百个数据点和几十个预测因子。这很可能是不够的,甚至可能会导致预测模型对公司数据的过度拟合的风险。

因此,他们将需要购买基于更大数据集构建的产品。问题是,他们不知道来自CRM提供商还是初创企业的产品才更适合他们。
在这里,现有企业的优势不太明确,初创企业可能仍然有很多机会。
特别是如果它们可以:
- 结合大型科技公司没有的不同数据来源(例如,Salesforce无法访问Hubspot的数据);或者,
- 生成额外的专有数据(下一部分将有更多介绍)。
剩下的空间可能是最大的机会所在:那些科技公司没有涉足且客户无法获得足够大数据集以实现足够好的通用机器学习效果的领域。农业和医疗保健的某些细分市场就是很好的例子,这些领域没有大型科技公司主导市场,每个客户只有少量数据可用。

在下一部分,我将深入探讨矩阵的左侧,特别是左下方的这个区域。
三、新的Moats
新方程式“成功 = 数据 * 数据 + 机器学习人才 + 算法”中的好消息是,当数据最初只有较小的数量可用时(假设数据<1),它对结果的影响比初始方程式更有限。机器学习人才和算法对输出的影响也更大,而现有企业拥有的优势也就减小了。
这就直接造成了,在数据稀缺的市场上,拥有正确的机器学习人才和创新算法的初创企业才会有机会蓬勃发展。
以下是三种方式(并不互斥),可以克服这种稀缺问题。
案例1:从多个客户收集数据
虽然每家公司单独来看可能没有足够大的数据集来构建出优秀的AI产品,但一个AI初创企业可以从多个客户那里汇集数据,从而成为唯一能够构建符合其期望的产品的公司。每个单独的参与者都会提供他们的数据,以便从更大的数据集上更好地训练算法。
想象一下,一个用于温室的SaaS解决方案可以将多个温室的数据结合起来,并得出最佳产量的预测。每个温室业主可能没有足够大的数据集,但会从一个AI代理构建更好的预测甚至控制整个温室中获益匪浅。
Tom Tunguz 在这篇文章领域汲取了一些经验并提出了一个有趣的观点。
案例2:智能系统
如果我们进一步推理,大量数据不可用的另一个原因是因为这些数据不仅在不同客户之间被隔离,而且在不同的SaaS工具之间也被隔离,其中一些是参与系统(例如网站、Slack),而另一些是记录系统(例如市场自动化工具、CRM)。
一个能够位于这两个数据集之间的AI初创企业才非常有可能构建出最佳的预测,并成为Jerry Chen在这篇文章中所称的智能系统。
再次考虑CRM的使用案例。潜在客户对营销材料的反应难道不是衡量他们购买可能性的良好指标吗?问题在于Salesforce没有这些数据,因为它被锁定在Hubspot的数据库中。
同样地,Hubspot不知道潜在客户在销售管道中的发展速度。因此,假设在这个市场中数据稀缺(矩阵的左侧),Salesforce和Hubspot都无法处于构建最佳预测的正确位置。一个在这两个数据库上构建预测模型的AI初创企业可能会在这个领域击败Salesforce和Hubspot。
一个很好的思考方式是将数据集视为价值链中的互补资产。新兴的、看似无害的AI初创企业可能会与一个现有企业永远不会愿意合作的公司合作,从而构建互补资产,保护它们免受这些现有企业的威胁。
与这个观点相对立的是,依赖于单一非专有数据源的公司要比结合多个数据源的公司更容易受到攻击。
归根结底,这一切都归结于回答这个问题:“谁从我的数据中获利?”是生成数据的公司吗?是存储数据的公司吗?还是在这些数据上构建最佳机器学习产品的公司?
这在AI初创企业中并不是新鲜事,但随着人们认识到他们数据的价值,它可能会带来全新的维度。就像Twitter杀死了所有开发替代Twitter客户端的公司一样,Salesforce可能会消灭那些过度在Salesforce中存储数据并且获利的初创企业。
还有一种解决数据所有权问题的最后一种情况。
案例3:拥有用户生成数据的独特数据集
如果一家公司无法从多个客户或多个SaaS工具中收集数据,或者收集到的数据不足以构建足够好的预测模型,那么它可以尝试从自己的SaaS产品中生成额外的数据。这是一个独特的机会,可以构建一份其他现有企业没有的专有数据集。
例如,我们的投资组合公司Juro开发合同管理软件,就构建了一个独特的数据集来了解合同的形成和谈判过程。
四、学习曲线
整个推理可以通过绘制学习曲线来概括,描述的是:“需要多少时间、精力或资金才能达到足够高的准确性,以满足客户的期望?”
在数据不稀缺的情况下,适用以下学习曲线:
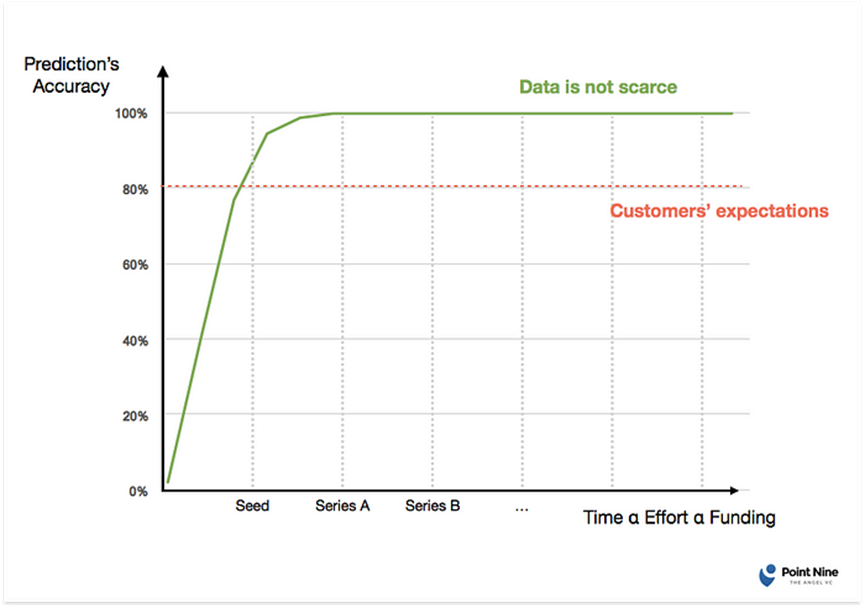
在很短的时间、精力和资金投入下,公司可以获得足够的数据来满足客户的期望。因此,其防御性相对有限。这特别适用于使用公开可获取的数据的情况。
在相反的情况下,当数据稀缺且需要大量时间、精力和资金时,学习曲线可能如下所示:

在这种情况下,需要大量的时间、精力和资金才能达到足够高的准确性,因此其防御性很强。
它的防御性尤其强,是因为在很久的时间内,客户可能都不会贡献他们的数据,数据网络效应也不会发生。
要记住,这些情况是非常理论的,只是为了提供一个思考数据网络效应带来的防御性的框架。
第二种情况下,数据稀缺可能会带来很高的防御性,但也可能是一个困难的处境,因为公司必须等到A轮融资之后才能满足客户的期望。
对于种子投资者来说,这也是一个困难的处境,因为我们不知道种子轮之后的曲线会是什么样子。这些曲线看起来像是S型曲线,但实际上可能不是。不确定的是产品是否能够足够好地为客户提供价值。
最后一点是,机器学习防御性和SaaS防御性并不是互斥的。非常长的产品路线图、优秀的用户体验或用户/数据锁定仍然是公司防御性的重要因素,超出了源自数据网络效应的防御性。
因此,如果你正在建立一个机器学习初创企业,无论你处于哪种情况,请随时与我联系,我很愿意和你探讨这个话题!
非常感谢Savina Van der Straten、Clement Vouillon 、Alex Flamant和Nathan Benaich 对本文(早期的草稿)进行的审查。
所有评论