
本文作者:Bo Ingram 编译:Cointime Candice
2017年,我们写了一篇关于如何存储数十亿条消息的文章。我们分享了我们如何开始使用MongoDB,但将数据迁移到Cassandra的过程,因为我们正在寻找一个可扩展、容错且维护相对较低的数据库。我们知道我们会成长,我们做到了!
我们想要一个与我们一起增长的数据库,但希望它的维护需求不会与我们的存储需求一起增长。不幸的是,我们发现情况并非如此——我们的Cassandra集群出现了严重的性能问题,需要付出更多的努力来维护,而不是改进。
差不多六年后,我们发生了很大变化,我们存储信息的方式也发生了改变。
我们的Cassandra难题
我们将消息存储在一个名为cassandra消息的数据库中。顾名思义,它运行Cassandra,并存储消息。2017年,我们运行了12个Cassandra节点,存储了数十亿条消息。
2022年初,它拥有177个节点,其中包含数万亿条消息。有一个缺点是,这是一个高风险的系统——我们的值班团队经常因为数据库的问题而被呼唤,延迟是不可预测的,我们不得不减少维护操作,因为维护操作变得过于昂贵,无法运行。
是什么导致了这些问题?首先,让我们来看一条消息。

上面的CQL预言是我们的消息模式的最小版本。我们使用的每个ID都是Snowflake,因此可以按时间排序。我们根据消息发送的通道以及一个存储桶来划分消息,这是一个静态时间窗口。这种分区意味着,在Cassandra中,给定通道和存储桶的所有消息都将存储在一起,并跨三个节点(或你设置的任何复制系数)进行复制。
在这种分区中存在一个潜在的性能隐患:只有一小群人的服务器发送的消息往往比拥有数十万人的服务器少几个数量级。
在Cassandra中,读比写更昂贵。写入被追加到提交日志中,并被写入一个叫做memtable的内存结构中,然后在磁盘上刷新。读取需要查询memtable和潜在的多个SSTables(磁盘上的文件),这是一个更昂贵的操作。当用户与服务器交互时,大量的并发读取会使分区成为热点,我们形象地称之为“热分区”。当我们的数据集的大小与这些访问模式相结合时,会使我们的集群陷入困境。
当我们遇到热分区时,它经常会影响整个数据库集群的延迟。一个通道和桶对接收到大量流量,并且随着节点越来越努力地服务流量,节点的延迟将增加,并且越来越落后。
由于该节点无法跟上,对该节点的其他查询也受到影响。由于我们用法定人数的一致性水平进行读写,所有对服务于热分区的节点的查询都会遭受延迟的增加,导致更广泛的终端用户影响。
群集维护任务也经常造成麻烦。我们很容易在压缩方面落后,Cassandra会将SSTables压缩到磁盘上以实现更高性能的读取。不仅我们的读取变得更加昂贵,而且当节点试图压缩时,我们还会看到级联的延迟。
我们经常执行一个我们称之为“八卦舞”的操作,在这种情况下,我们会将一个节点从轮换中取出,让它在不占用流量的情况下进行压缩,然后将其带回,以从Cassandra暗示的切换中获取提示,然后重复,直到压缩积压工作清空。我们还花了大量时间调整JVM的垃圾收集器和堆设置,因为GC暂停会导致显著的延迟峰值。
改变我们的架构
我们的消息集群不是我们唯一的Cassandra数据库。我们还有其他几个集群,每个集群都表现出类似的故障(尽管可能没有那么严重)。
在上一篇文章中,我们提到了对ScyllaDB的兴趣,这是一个用C++编写的与Cassandra兼容的数据库。它所承诺的更好的性能、更快的修复、通过其每核分片架构实现更强的工作负载隔离,以及无垃圾收集的生活,听起来相当吸引人。
尽管ScyllaDB不是绝对的没有问题,但它是没有垃圾收集器的,因为它是用C++而不是Java编写的。从历史上看,我们的团队在Cassandra上的垃圾收集器上遇到过许多问题,从GC暂停影响延迟,到超长的连续GC暂停,这些暂停非常糟糕,以至于操作员必须手动重新启动并照看有问题的节点恢复健康。这些问题导致需要有人值班,也是我们消息集群中许多稳定性问题的根源。
在使用ScyllaDB进行实验并观察到测试的改进后,我们决定迁移所有数据库。虽然这个决定本身可以写成一篇博文,但简短的说,到2020年,除了一个数据库,我们已经将所有的数据库迁移到ScyllaDB。
最后一个?我们的朋友,cassandra-messages。
为什么我们还没有迁移呢?首先,它是一个大集群。由于有数万亿条消息和近200个节点,任何迁移都将是一项复杂的工作。此外,我们想确保我们的新数据库在调整其性能时可以做到最好。我们还希望在生产中获得更多的ScyllaDB经验,在愤怒中使用它并学习它的缺陷。
我们还努力提高ScyllaDB在我们的使用案例中的性能。在我们的测试中,我们发现反向查询的性能不足以满足我们的需求。当我们试图以与表的排序相反的顺序进行数据库扫描时,例如当我们以升序扫描消息时,我们会执行反向查询。ScyllaDB团队优先改进并实施了高性能的反向查询,消除了我们迁移计划中最后一个数据库障碍。
我们怀疑,在我们的系统上建立一个新的数据库不会让一切神奇地变好。热分区在ScyllaDB中仍然是一个问题,因此我们还想投资于改进数据库上游的系统,以帮助屏蔽和促进更好的数据库性能。
用数据服务来服务数据
在Cassandra中,我们为热分区而挣扎。某个分区的高流量导致了无限制的并发,导致了级联延迟,即后续查询的延迟会继续增长。如果我们能控制热分区的并发流量,我们就能保护数据库不被压垮。
为了完成这项任务,我们编写了我们所称的数据服务——位于API单体和数据库集群之间的中间服务。在编写我们的数据服务时,我们选择了一种我们在Discord越来越多地使用的语言:Rust!我们之前曾在几个项目中使用过它,它没有辜负我们的期望。在不牺牲安全性的情况下,它为我们提供了快速的C/C++速度。
Rust将无畏的并发性标榜为其主要优点之一——该语言应使编写安全的并发代码变得容易。它的库也与我们想要实现的目标非常匹配。Tokio生态系统是建立异步I/O系统的巨大基础,该语言同时支持Cassandra和ScyllaDB的驱动程序。
此外,错误消息的清晰性、语言构造以及对安全性的强调,让我们发现在编译器提供的帮助下编写代码是一件很愉快的事情。我们变得相当喜欢它,因为它一旦编译,一般都能工作。然而,最重要的是,它让我们可以说我们是用Rust重写的(meme信用非常重要)。
我们的数据服务位于API和ScyllaDB集群之间。它们每个数据库查询大约包含一个gRPC端点,并且故意不包含业务逻辑。我们的数据服务提供的主要功能是请求合并。如果多个用户同时请求同一行,我们将只查询数据库一次。发出请求的第一个用户会引起工作任务在服务中启动。随后的请求将检查该任务的存在并订阅它。该工作任务将查询数据库并将该行返回给所有订阅者。
这就是Rust的作用:它使编写安全的并发代码变得容易。
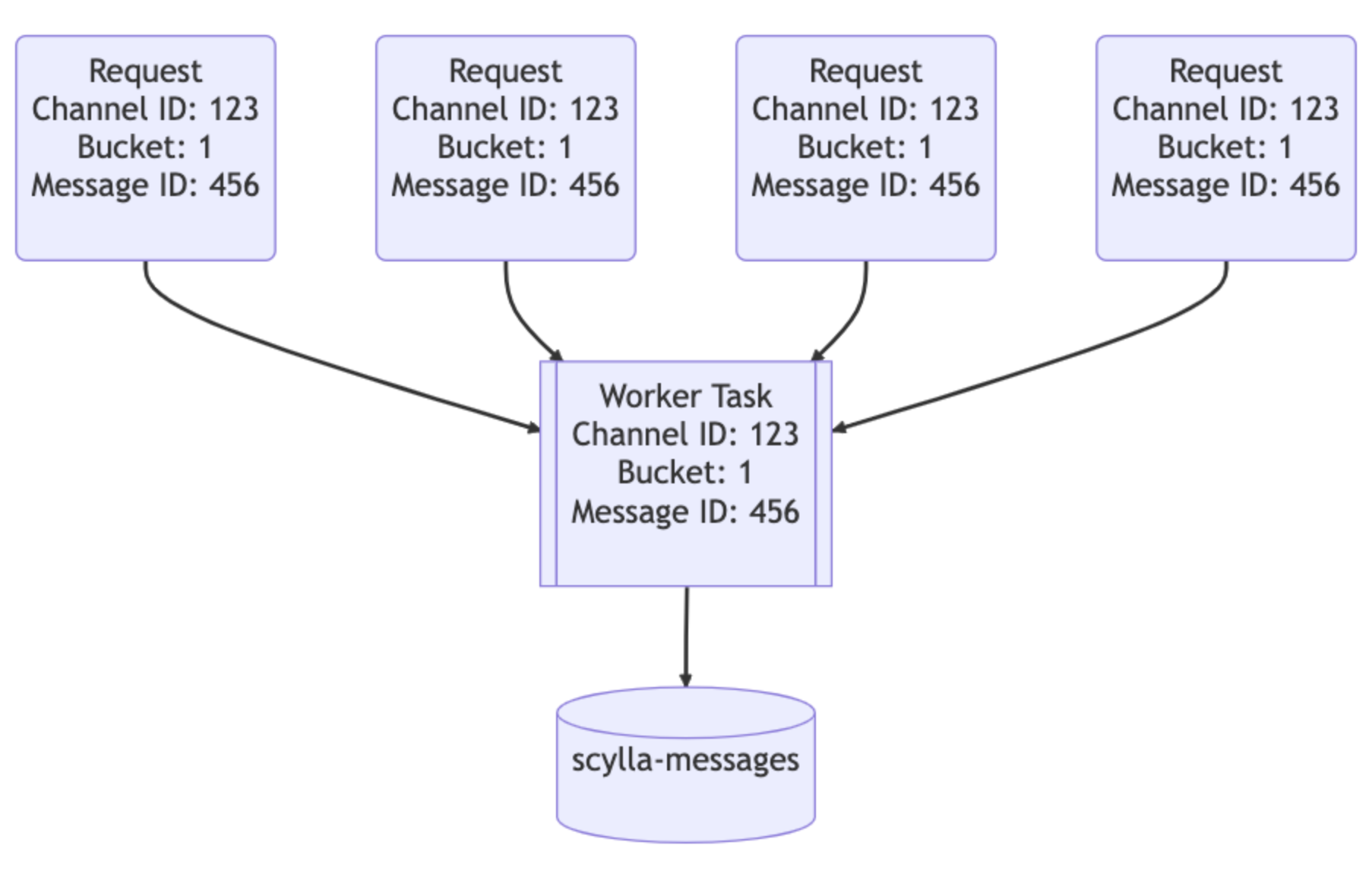
让我们想象一下,在一个大型服务器上有一个通知@所有人的大公告:用户将打开应用程序并阅读消息,向数据库发送大量流量。以前,这可能会导致热分区,并且可能需要调用页面来帮助系统恢复。通过我们的数据服务,我们能够明显减少数据库的流量高峰。
神奇的第二部分是我们数据服务的上游。我们对数据服务实施了一致的基于哈希的路由,以实现更有效的合并。对于数据服务的每个请求,我们都提供一个路由密钥。对于消息来说,这是一个通道ID,所以所有对同一信道的请求都会被送到服务的同一个实例中。这种路由进一步帮助减少我们数据库的负载。
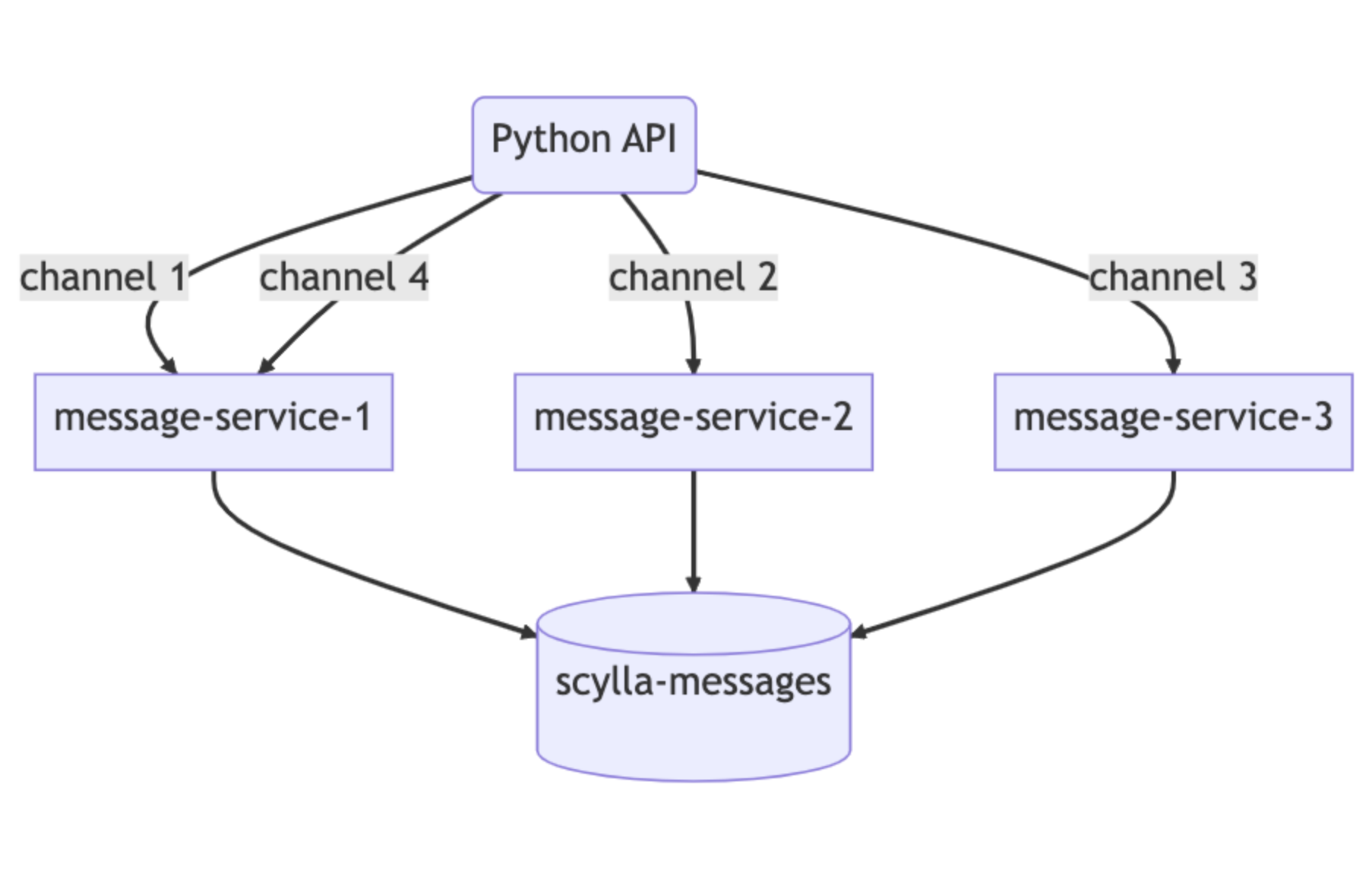
这些改进有很大的帮助,但它们还不能解决我们所有的问题。我们仍然在我们的Cassandra集群上看到热分区和延迟增加的问题,只是没有那么频繁。但这为我们赢得了一些时间,以便我们可以准备新的最佳ScyllaDB集群并执行迁移。
大迁移
我们对迁移的要求非常简单:我们需要在不停机的情况下迁移数万亿条消息,而且我们需要尽快完成,因为虽然Cassandra的情况有所改善,但我们仍然经常在救火。
第一步很简单:我们使用超级磁盘存储拓扑提供一个新的ScyllaDB集群。通过使用本地SSD提高速度并利用RAID将数据镜像到持久磁盘,我们可以获得连接的本地磁盘的速度和持久磁盘的耐久性。随着集群的建立,我们可以开始将数据迁移到其中。
我们的迁移计划初稿旨在快速实现价值。我们将开始使用我们闪亮的新ScyllaDB集群,使用切换时间获取更新的数据,然后在其后面迁移历史数据。这使迁移变得更复杂,但每个大型项目都需要额外的复杂性,对吗?
我们开始向Cassandra和ScyllaDB双重写入新数据,同时开始提供Scylla DB的Spark迁移器。这需要大量的调整,一旦我们把它设置好,我们有一个估计的时间来完成:三个月。
这个时间框架不会让我们感到内心温暖,我们更希望更快地获得价值。我们作为一个团队坐下来,集思广益,想办法加快进度,直到我们想起我们已经写了一个有可能扩展它的快速和高性能的数据库集。我们选择参与一些meme驱动的工程,用Rust重写数据迁移器。
在一个下午的时间里,我们扩展了我们的数据服务库来执行大规模的数据迁移。它从数据库中读取代币范围,通过SQLite对其进行本地检查,然后将其导入ScyllaDB。我们把我们新的和改进的迁移器连接起来,得到一个新的估计:9天!这是一个新的估计。如果我们能够如此快速地迁移数据,那么我们就可以忘记我们复杂的基于时间的方法,而一次性切换所有内容。
我们打开它并让它运行,以每秒320万的速度迁移消息。几天后,我们聚集在一起看着它达到100%的过程,我们意识到它停留在99.9999%的完成度上(不,真的)。我们的迁移器正在超时读取最后几个代币范围的数据,因为它们包含在Cassandra中从未压缩过的巨大范围的文件。我们压缩了代币范围,几秒钟后,迁移就完成了!
我们通过向两个数据库发送一小部分读取数据并比较结果来执行自动数据验证,一切看起来都很好。集群在满负荷生产流量下运行良好,而Cassandra则面临着越来越频繁的延迟问题。我们在团队现场聚集在一起,打开开关,使ScyllaDB成为主要数据库,分享成功的喜悦!
几个月后……
我们在2022年5月切换了我们的消息数据库,但从那以后它是如何保持的?
这是一个平稳、表现良好的数据库(可以这么说,因为我本周不在值班)。我们没有周末长时间的运行,也没有在集群中处理节点以试图保持正常运行时间。它是一个更有效的数据库,我们将从运行177个Cassandra节点变为仅运行72个ScyllaDB节点。每个ScyllaDB节点有9 TB的磁盘空间,高于每个Cassandra节点的平均4 TB。
我们的尾部延迟也有了很大的改善。例如,在Cassandra上,获取历史消息的p99在40-125ms之间,ScyllaDB的p99延迟为15ms,并且消息插入性能从Cassandra的5-70ms p99提高到Scylla数据库的稳定5ms p99。由于前面提到的性能改进,我们已经解锁了新的产品用例,现在我们对消息数据库很有信心。
2022年底,全世界的人都在看世界杯。我们很快发现的一件事是,进球显示在我们的监测图表中。这很酷,因为不仅可以看到真实世界的事件出现在你的系统中,而且这给了我们团队在会议期间观看足球的借口。我们不是“开会时看足球”,而是“主动监测我们的系统性能”。

我们实际上可以通过我们的信息发送图来讲述世界杯决赛的故事。这场比赛非常精彩。梅西正在努力完成他职业生涯中的最后一项成就,巩固他作为有史以来最伟大的球员的地位,并带领阿根廷队夺冠,但挡在他前面的是才华横溢的姆巴佩和法国队。
这张图中的九个尖峰都代表了比赛中的一个事件。
- 梅西罚中点球,阿根廷以1比0领先。
- 阿根廷队再次得分,以2:0领先。
- 现在是中场休息时间。当用户谈论比赛时,有一个持续15分钟的平稳期。
- 这里的大高峰是因为姆巴佩为法国队进球,并在90秒后再次进球,将比分扳平!
- 这是规定的结束时间,这场大型比赛将进入加时赛。
- 加时赛的前半段发生的事情并不多,但我们到了中场休息时间。
- 梅西再次进球,阿根廷队领先!
- 姆巴佩反击,将比分扳平!
- 加时赛结束了,我们将进入点球大战!
- 兴奋和压力在整个点球大战中不断增加,直到法国队失误,而阿根廷队没有失误! 阿根廷获胜!
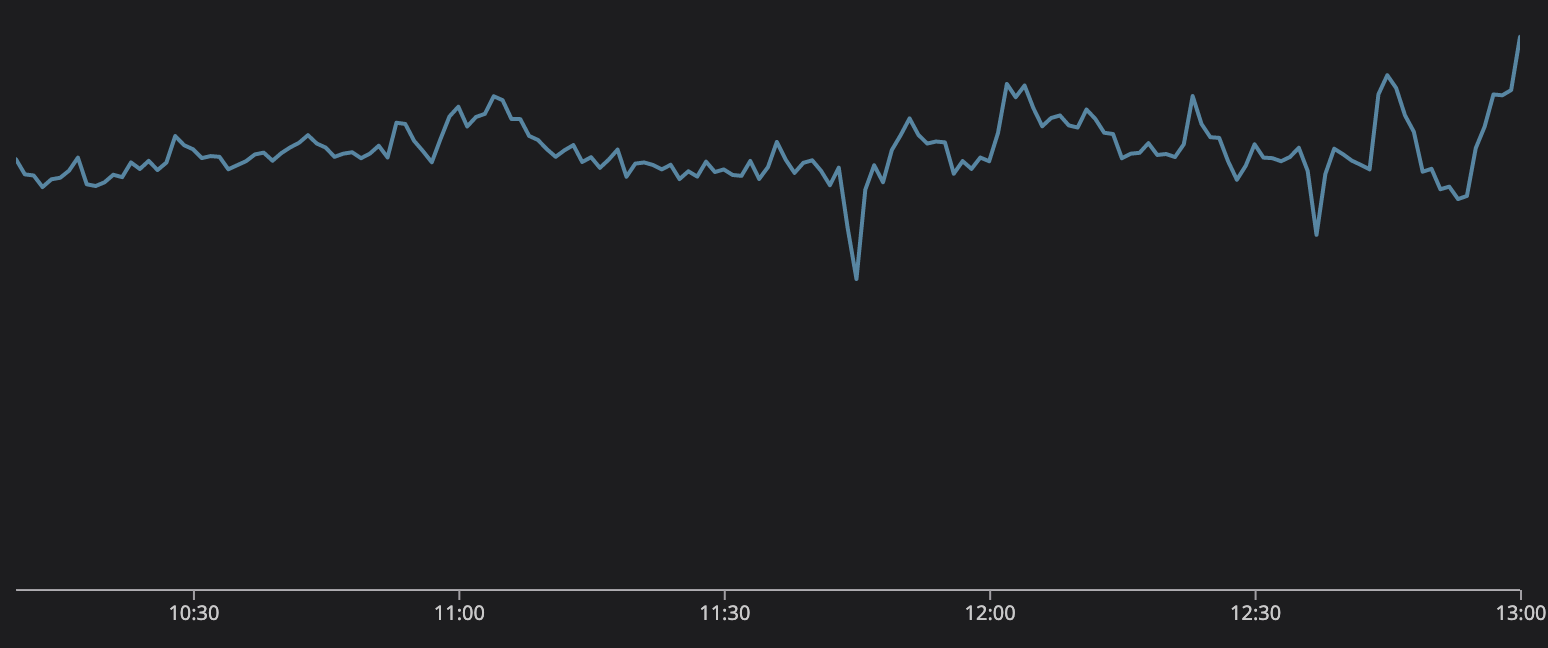
全世界的人都在紧张地观看这场令人难以置信的比赛,但与此同时,Discord和信息数据库并没有担心。我们的消息发送量很大,而且处理得很好。 通过我们基于Rust的数据服务和ScyllaDB,我们能够承担这些流量并为我们的用户提供一个交流平台。
*本文由CoinTime整理编译,转载请注明来源。
所有评论